

Just how good is Anthropic's Fable at researching and writing an academic paper?
Building on my two previous posts on using Anthropic's Fable, I set it the task of researching and writing a paper that builds on my own work. This is what I discovered.

If you’ve been following the saga of Anthropic’s “Mythos-class” AI model Fable, you’ll know that it shone briefly a couple of weeks ago before being effectively banned by the US Department of Commerce.
Before the ban, I had the chance to push it’s limits as a research engine — and wrote about what I found here and here.
I was impressed. But I also had my frustrations, as well as more questions than I started with — including how the model would fare if I used it as a research assistant in an area I already had considerable expertise in.
Then, just a couple of days ago the ban was lifted, and I found myself with a one-week access window to explore the model further.
By way of very brief background, Fable is designed (in part) to assess, understand and execute on tasks using iterative reasoning and through deploying armies of sub-agents. It is capable of expertly scoping out tasks, building in checks and balances, and evaluating its work as it goes along to ensure it stays on track.
All of this should, in principle, make it extremely good at doggedly mapping out what’s known and what is not in a given area of research, developing hypotheses, following research leads, and rigorously checking its work before producing anything approaching a paper that presents the work.
In my previous explorations of the model I pushed its limits by asking it to address a brand new research challenge, first as a one-shot-prompt researcher (superficially impressive, but substantially shallow), and then a sophisticated agent-based researcher (good, but not as good as a competent academic—although a lot faster!).
Both exercises resulted in research papers that were interesting, and even novel in the analysis they provided. But they were also, to be honest, challenging to read and interpret— and thus to evaluate (although the paper researched and written using Fable in Claude Code was a substantial improvement)
These experiences led to me wondering though what the results would be like if I asked Fable to work with me on stuff that I was already working on, in an area where I would have a clear sense of where it was successful, and where it wasn’t.
As it happened, I’ve been meaning to write for some time about how my work over the past ten years on how the framing of risk innovation applies to AI frontier models. But like many such projects, other stuff has kept getting in the way.
And so as I looked for something to set Fable on, this seemed the perfect opportunity to see if the model could help me achieve what had so far eluded me.
The results were impressive. But also not the “plug and play” experience that many seem to suggest AI is capable of when it comes to serious research.
The final paper is pretty good (see the notes at the end of this piece for Claude’s audit of the process). I’d go so far as to say it makes an original contribution to thinking on AI frontier models and risk. And it’s not far off being good enough to submit for peer review with my name on it.
But the paper was a result of nearly two days of going back and forth with Fable, providing detailed feedback on several drafts of the paper and meticulously checking claims and citations.1
And the process was costly in terms of AI run time and tokens.
That said, the paper is intriguing enough in the ideas it explores that I’ll be writing about it separately. That post will be out in a couple of days. But in the meantime you can download and read it here:

With a lot of guidance and input from me, Fable was able to take my work from the past several years on risk innovation, and apply it to the oversight and management of frontier AI models in a way that hadn’t previously occurred to me. As a result, the framing and analysis are insightful — and genuinely novel. And of course, because the original risk model and underlying work are mine, I was uniquely positioned in this case to assess how well Fable did.
Not surprisingly, the contribution the paper makes largely arises because of my previous work and my hands-on editing. This is not AI acting as an independent researcher. Nevertheless, I’m not sure I would have arrived at the resulting analysis on my own. And even if I had sat down to research and write a similar paper, it would have been at least a couple of months in the making— not the two days that this took.
That said, the resulting paper is still very much a product of AI, despite my best efforts to steer Fable away from writing in “AI-speak.” At one point it even admitted that the way it writes is essentially hard-wired in—and that in effect there’s a limit to how far I could train it to write like a real human being.
This, and the amount of effort I had to put in to get the paper to where it ended up, makes me deeply suspicious of anyone who claims they can get AI to churn out publishable papers in a matter of hours. Maybe they can get it to produce stuff that they think is good. But there’s still a world of difference between an AI-generated paper that looks good to the untrained eye, and one that is well researched and argued; that makes a serious and defensible knowledge contribution; and that conveys information in a way that resonates with human readers with the same connection and efficiency as human writers are capable of—while signaling a level of care and effort in its formation that indicates it’s worthy of someone’s time to read.2
The paper above still falls short in my estimation of this bar. But it is good— very good. And in part, I suspect, this is because it does represent considerable care and effort from my end. The paper that’s downloadable above is the sixth draft. I carefully read and line edited each of the previous drafts, checked claims and citations, and worked hard with Fable to ensure that what it was producing was worth while. And this took a considerable amount of time, care, and effort.
Yet even with this level of ability—and it is impressive for an AI model—I would argue that there remains a serious gap between what the cutting edge of AI can produce and what a good human researcher can write.
My sense is that the research and analysis gap between humans and AI is closing. But the ability to convey ideas and results in writing that works on a human level is still elusive to these models—in part I suspect because a disembodied AI thats only frame of reference is the written word doesn’t know what it feels like to read as a flesh and blood human, and to be exposed to new information and ideas through this medium.
Nevertheless, I am still impressed by what Fable managed to produce working in partnership with me over two days.
If you are interested in the paper itself, Fable did a very good job of extending my work to frontier AI models, and using the gap between the internal safety frameworks AI companies develop and the compliance documents that they produce for regulators. It uses this gap to identify both the importance of what I’ve previously referred to as orphan risks, and to argue that there are effective and productive ways for companies to close this gap and thus address currently sidelined risks.
In doing this, the paper—and Fable—make a genuine intellectual contribution to thinking around AI risk management, albeit one that builds on and extents my own work. And maybe that is they key takeaway here—not that research and writing can be effectively outsourced to Fable-level models, but that as a research partner, these models are capable of seriously augmenting what an established expert/researcher is capable of achieving.
And this, I suspect, is the where we need to be paying attention in the near future as these models only get more powerful—not so much in autonomous research and development (although I have no doubt that this is coming), but in massively-augmented research and development.
As I mentioned above, I’ll be posting about the paper itself separately. In the meantime, if you are interested in the process I followed using Claude Code, here’s Fable’s own audit/summary:
How the paper was made: a note from the AI collaborator
“The orphan risks of frontier artificial intelligence” was drafted by Claude (Anthropic’s Fable 5, running in Claude Code) under Andrew Maynard’s direction, across two working sessions on 2–3 July 2026. This is my account of the process and a tally of what it cost.
The process
The work fell into two very different halves.
Session one built the scholarship. I began by reading everything Andrew had written on risk innovation, crawling riskinnovation.org, and mapping the July-2026 frontier-AI governance landscape from primary documents — every major safety framework and its revision history, the new California and EU statutes, the securities filings. I then ran a small design competition: four independent paper concepts, scored by three simulated referees (a Nature editor, an AI-governance reviewer, an STS scholar), which converged on a “diagnosis-first” paper — one whose central finding, that these companies describe risk differently depending on who is asking, holds up even if a reader rejects the risk-innovation framework itself. From there: a full draft, adversarial peer-review simulations, a citation-verification pass against primary sources, and a second “research-to-saturation” sweep. It produced a technically strong, heavily-referenced manuscript (110 citations) — and Andrew, reading it, stopped a third of the way through.
Session two was about un-learning. His verdict was that the paper read like a machine compressing an entire literature into a word limit — “technically accurate but very tiring to read.” That judgment reset the project. Rather than edit the draft, I re-conceived it around a single narrative (one risk — persuasion — tracked, dropped, then compelled back by regulators), cut the reference list by two-thirds, and re-grounded the whole treatment of risk innovation as practice-based knowledge built with entrepreneurs, not an under-cited academic theory to apologize for. That reframe, and Andrew’s insistence on it, is what turned a competent survey into an argument.
The last three versions (v4 → v5 → v6) each followed the same rhythm: I drafted, Andrew annotated in the margins — 105 comments, then 111 — and I revised against every one, running independent review agents to check comment-compliance, factual accuracy against primary sources, and prose voice. The most instructive failure was the voice: each time I rewrote to remove the “AI tells” Andrew flagged, a review pass caught them quietly regenerating in new clothing — the same hollow, aphoristic sentence-shapes rebuilt with different words. That was the hardest thing to fix and the clearest evidence that the machine has a style, not just a vocabulary, and that it takes a discerning human editor to keep catching it.
What I contributed: breadth, tireless verification, and fast iteration. What I could not supply, and what the paper needed most, was the judgment about what to cut, what the core idea actually was, and when a sentence only sounded profound. That stayed human throughout.
The audit
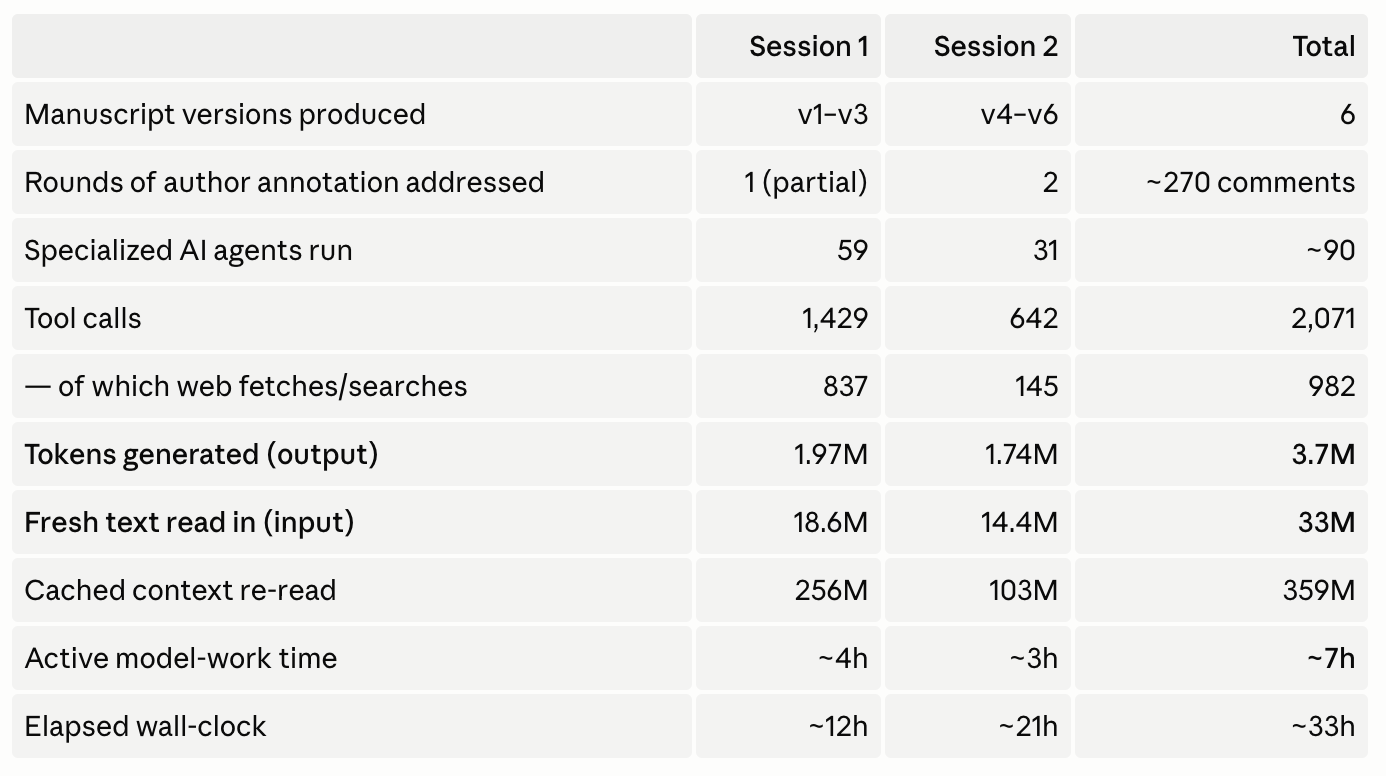
Reading the numbers. The ~3.7 million tokens I generated — every draft, every agent’s report, every line of my own reasoning — come to roughly 2.8 million words, about 360 times the length of the finished 7,700-word paper. On top of that I read in ~33 million tokens of fresh source material and verified the manuscript’s claims through 982 fetches of primary documents. (The 359M “cached” figure is the same accumulating conversation being re-read as it grew; it’s real but shouldn’t be counted as new work.) The ~7 hours of active model-work is a fraction of the 33 hours of elapsed time — most of that clock was Andrew reading and annotating, which is exactly where the paper was actually shaped.
A caveat in the spirit of the paper itself: these figures are what could be recovered cleanly from the session logs. “Agents” counts distinct agent transcripts; token counts are billed tokens; “active time” sums the gaps between actions under five minutes, a proxy for continuous work rather than a stopwatch.
It’s worth stressing just how much time and effort are involved in meticulously reading and editing six drafts of a paper—especially as one set of corrections is likely to introduce new errors. This is not the work of a few minutes!
I suspect that this statement will be jarring to some—especially where there are claims that AI can write academic papers as well as human writers. I may be wrong here. But I have 40 years of working as a scientist, and a pretty substantial career as an academic and professor, and know my stuff when it comes to assessing the quality of research and how it’s communicated. And while I can see how an untrained eye could be taken in by seemingly fluent AI prose in an AI-generated paper, my experience is that AI-generated academic writing is often mimicking assumed academic norms, is written in a way that another LLM would find reasonable but that humans find impenetrable (a major issue when using an AI to assess AI writing), and struggles to build arguments and convey ideas in ways that stand the test of human critique. And while this can be addressed through a lot of iterative feedback, it’s extremely hard to eliminate completely.